Pourquoi l’auto-déclaration des opérateurs ne suffit plus aux régulateurs
Imaginez une situation qui pourrait se produire dans les bureaux de régulation à travers les économies émergentes et en développement.
Une autorité nationale des télécommunications vient de finaliser une analyse de la performance du haut débit fixe sur son marché. Les données présentées, fournies par les opérateurs eux-mêmes, indiquent des vitesses de téléchargement moyennes largement supérieures aux seuils réglementaires, une disponibilité dépassant les 99 %, et une qualité de service globalement conforme aux engagements annoncés.
Puis quelqu’un dans la salle pose une question : comment savons-nous réellement que cela est vrai ?
C’est une question simple, mais pour de nombreux régulateurs, la réponse n’est pas aussi claire qu’elle devrait l’être.
Les données fournies par les opérateurs peuvent être difficiles à vérifier de manière indépendante. Le régulateur peut ne pas disposer de mesures continues et réelles de l’expérience utilisateur. Et si un ministère, une banque de développement ou un bailleur international demande des preuves qu’un programme public de haut débit produit réellement des résultats, le régulateur peut se retrouver à s’appuyer principalement sur des données fournies par l’entité même qu’il est censé superviser.
C’est l’un des défis fondamentaux de la régulation télécom aujourd’hui et il devient de plus en plus difficile à ignorer.
Les limites de l’auto-déclaration

Les opérateurs télécoms sont des entités commerciales. Leurs rapports sont naturellement influencés par leurs objectifs opérationnels, commerciaux et réglementaires. Cela ne signifie pas qu’ils falsifient les données, mais que les indicateurs qu’ils produisent et l’expérience réellement vécue par les utilisateurs ne mesurent pas toujours la même chose.
Les opérateurs mesurent généralement la performance depuis l’intérieur du réseau : au cœur du réseau, au niveau des nœuds ou au point d’interconnexion. Ces mesures reflètent des performances théoriques ou maximales dans des conditions contrôlées.
En revanche, elles ne capturent pas ce que vit réellement une utilisatrice dans une zone périurbaine lorsqu’elle ouvre son logiciel de comptabilité à 9h un lundi, ni si un étudiant dans une zone rurale peut suivre un cours en ligne sans interruption.
" L’écart entre la performance mesurée côté réseau et l’expérience utilisateur réelle est là où apparaissent les angles morts réglementaires*"*
L’investissement public exige une responsabilité publique
Les enjeux ont fortement augmenté ces dernières années. Dans les marchés émergents, les gouvernements consacrent des investissements importants aux programmes nationaux de haut débit, souvent soutenus par des fonds de service universel (USF), des institutions de financement du développement ou des bailleurs internationaux tels que la Banque mondiale et la Banque africaine de développement.
Ces mécanismes de financement s’accompagnent d’exigences en matière de redevabilité. Les bailleurs souhaitent de plus en plus disposer de preuves crédibles que les investissements atteignent les utilisateurs finaux et produisent un impact mesurable. Des données de performance indépendantes peuvent jouer un rôle clé pour donner aux régulateurs cette assurance.
Un régulateur incapable de produire ces preuves peut se retrouver dans une position délicate. Il peut avoir des difficultés à rassurer les parties prenantes gouvernementales quant à l’atteinte des objectifs du programme. Il peut également lui être plus difficile de rendre compte de manière crédible à un bailleur international. Enfin, engager des actions contre un opérateur sous-performant devient plus complexe si le régulateur ne dispose pas de données indépendantes pour étayer son dossier.
Il ne s’agit pas de cas isolés. Cela reflète une évolution plus large dans la manière dont les régulateurs envisagent leur rôle en matière de preuve.
Pourquoi les anciens modèles de mesure ne passent pas à l’échelle
Les régulateurs sont conscients de ce problème. Une réponse traditionnelle a consisté à déployer des équipements matériels in-line à des points clés du réseau, avec des sondes physiques intégrées dans l’infrastructure de l’opérateur pour capturer des données au niveau du trafic.
Dans les marchés disposant d’une infrastructure réglementaire mature et de capacités techniques fiables, ce modèle peut fonctionner. Mais pour de nombreux régulateurs dans les marchés émergents, il introduit trois contraintes majeures.
Coût
Les déploiements de matériel in-line peuvent nécessiter des investissements en capital importants, une infrastructure serveur locale et un support informatique continu. Pour les régulateurs disposant de budgets limités, cela peut être difficile à justifier ou à maintenir à une échelle significative.
Dépendance à la coopération des opérateurs
La surveillance in-line nécessite un accès physique au réseau de l’opérateur. En pratique, cela signifie que les régulateurs dépendent de la coopération technique de l’entité même qu’ils surveillent, un conflit structurel qui peut retarder ou compliquer les mesures.
Instantanés ponctuels plutôt que données continues
De nombreux régulateurs s’appuient encore sur des campagnes de drive tests périodiques ou des contrôles ponctuels. Ceux-ci peuvent être coûteux, peu fréquents, et mal adaptés à la génération d’un historique continu et longitudinal nécessaire à l’application des règles, au reporting de conformité ou à l’analyse des tendances.
Le résultat est un déficit de mesure qui peut laisser la plupart des régulateurs sans la qualité de données ni la couverture opérationnelle nécessaires pour exercer leur mission de supervision en toute confiance.
À quoi ressemble réellement une supervision indépendante en conditions réelles
L’évolution en cours dans les marchés réglementaires les plus avancés consiste à adopter une architecture fondamentalement différente : une supervision qui se connecte au réseau, se comporte comme un équipement utilisateur réel et mesure le service tel qu’il est réellement vécu par l’utilisateur final.
Cette approche, parfois appelée supervision QoS client-based ou cloud-native, présente plusieurs avantages structurels par rapport aux modèles traditionnels. Les agents se connectent aux services haut débit exactement comme le ferait un équipement client standard, ce qui signifie qu’ils mesurent des performances réelles et interagissent avec le réseau de la même manière qu’un utilisateur. Ils ne nécessitent aucun accès in-line au réseau, ce qui réduit la dépendance à la coopération des opérateurs. Et parce qu’ils fonctionnent en continu sur une infrastructure cloud, ils génèrent un jeu de données longitudinal ininterrompu, indispensable pour le benchmarking, le contrôle et le reporting.
Des solutions telles que la plateforme de monitoring indépendant du haut débit d’Epitiro reposent sur ce modèle, en fournissant aux régulateurs des agents plug-and-go pouvant être déployés rapidement et commencer à générer des données de performance fiables et représentatives de l’expérience réelle, sur plusieurs opérateurs.
De manière critique, cette architecture est nettement plus économique à déployer à grande échelle, ce qui la rend viable pour les régulateurs dans des marchés où les modèles traditionnels in-line étaient difficiles à maintenir. Un déploiement ciblé d’agents plug-and-go dans une capitale ou une zone prioritaire peut fournir une vision continue et indépendante de la performance du haut débit sur plusieurs opérateurs, sans infrastructure locale de stockage ou de contrôle, sans équipe IT spécialisée, et sans dépendance à l’accès au réseau des opérateurs.
La couche analytique: transformer les mesures en intelligence réglementaire avec la plateforme Synaptique
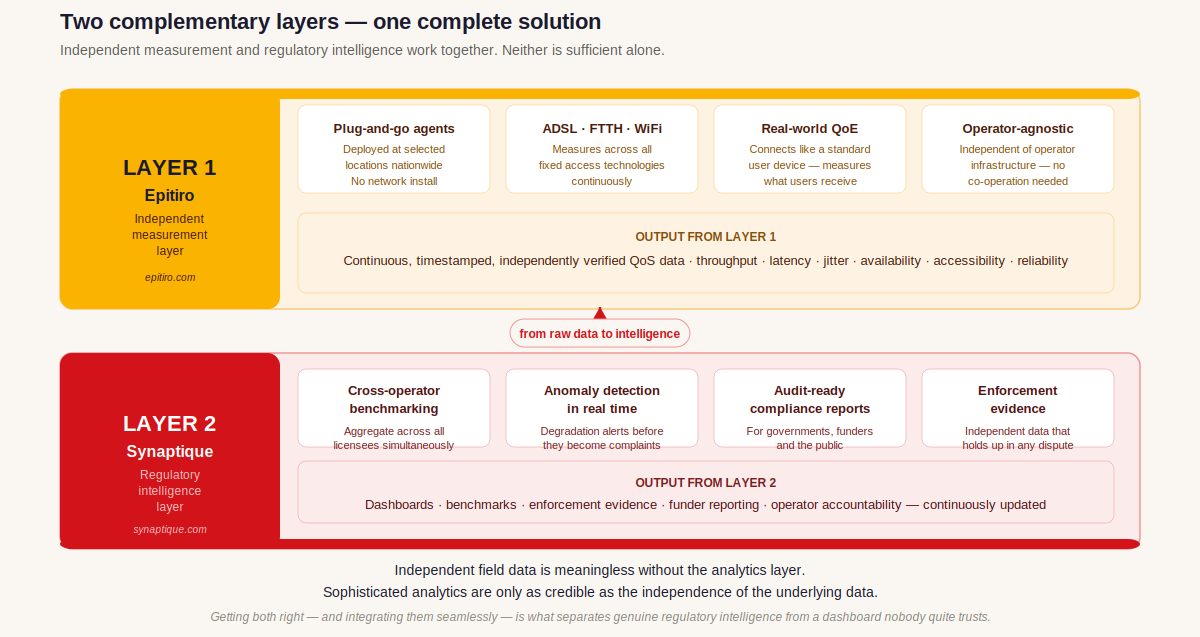
Les données brutes de mesure, même recueillies de manière indépendante, ne valent que par la capacité du régulateur à les interroger, les contextualiser et agir sur leur base. C’est ici que la connexion entre la mesure terrain indépendante et l’analytique avancée devient déterminante.
Chez Synaptique, nous accompagnons les régulateurs dans la mise en place de la couche analytique qui s’appuie sur les données QoS collectées indépendamment : ingestion continue des flux de mesure, agrégation des performances par opérateur et par zone géographique, détection en temps réel des anomalies et des dégradations, ainsi que génération de tableaux de bord exploitables et de rapports de conformité prêts pour audit.
La couche de mesure et la couche analytique sont distinctes mais profondément complémentaires. Les données terrain indépendantes sont inutiles sans outils pour les traiter et les présenter. Une analytique sophistiquée n’est crédible que si la qualité et l’indépendance des données sous-jacentes sont garanties.
"Les données terrain indépendantes deviennent plus puissantes lorsque les régulateurs disposent des outils pour les traiter et les présenter. Des analyses sophistiquées ne sont crédibles que si l’indépendance et la qualité des données sous-jacentes sont assurées."
La direction est claire
Les régulateurs télécoms à travers le monde évoluent de plus en plus vers des modèles reposant sur des données QoS indépendantes, collectées en continu et agnostiques vis-à-vis des opérateurs, afin de renforcer leur capacité de supervision.
Les gouvernements qui investissent des fonds publics dans le déploiement du haut débit exigent des preuves plus solides de la réalisation des objectifs. Les bailleurs internationaux accordent également une importance croissante aux résultats mesurables et à des rapports crédibles. Et de nombreuses autorités de régulation tournées vers l’avenir reconnaissent que leur crédibilité dépend de leur capacité à disposer d’une vision claire et indépendante de l’expérience réelle des utilisateurs.
Les barrières techniques et économiques qui rendent cela difficile se sont également réduites. Les architectures basées sur des agents cloud ont rendu la supervision indépendante plus abordable et plus scalable pour des régulateurs qui n’auraient jamais pu soutenir un déploiement traditionnel in-line ou une infrastructure locale.
La question est de moins en moins de savoir si la supervision QoS indépendante est faisable, et de plus en plus de comprendre comment les régulateurs peuvent la mettre en œuvre de manière pratique et proportionnée , et comment ils peuvent construire la capacité analytique nécessaire pour transformer ces données en véritable intelligence réglementaire.