Implémentation de l'Architecture Médaillon pour l'Assurance Revenus Télécom
Dans l'industrie des télécommunications, le traitement efficace et précis des enregistrements de données d'appel (CDR) est essentiel pour l'assurance revenus, la détection de fraude et l'optimisation du réseau. Cet article explore comment implémenter une architecture médaillon moderne en utilisant Apache NiFi, Spark, les tables Iceberg et dbt pour construire une plateforme de données télécom évolutive.
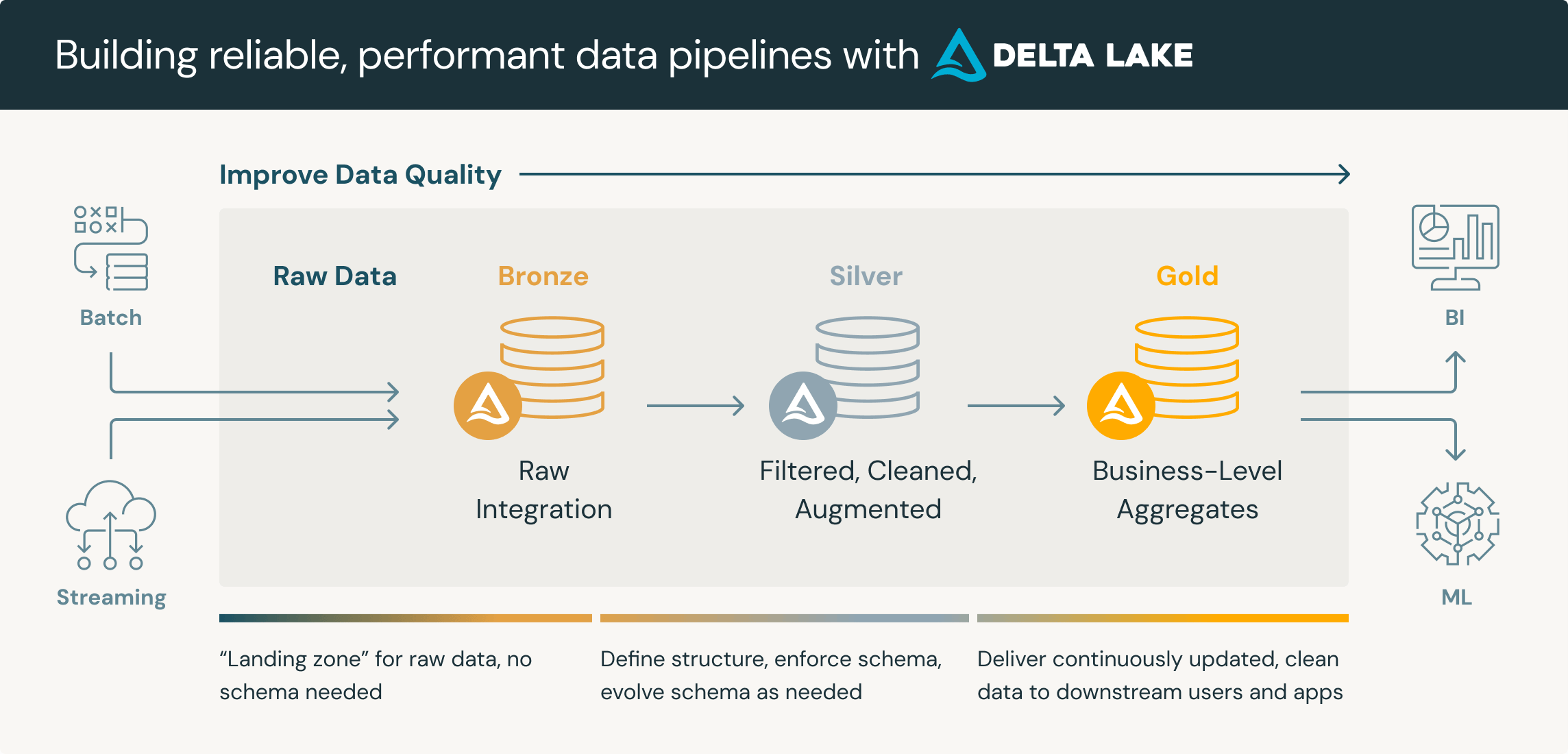
Vue d'Ensemble de l'Architecture
Notre plateforme de données télécom implémente le modèle d'architecture médaillon à travers trois couches :
- Couche Bronze : Ingestion de CDR bruts utilisant Apache NiFi et Spark avec décodage ASN.1
- Couche Silver : Données nettoyées et corrélées stockées dans des tables Apache Iceberg
- Couche Gold : Métriques métier agrégées préparées avec dbt pour la visualisation BI
Le Défi des Données Télécom
Les réseaux de télécommunications génèrent des volumes massifs de CDR provenant de multiples éléments réseau :
- MSC (Mobile Switching Center) : Enregistrements d'appels vocaux
- SMSC (SMS Center) : Enregistrements SMS/MMS
- GGSN/PGW (Packet Gateway) : Enregistrements de sessions de données
- OCS (Online Charging System) : Événements de taxation en temps réel
Chaque système produit des CDR dans différents formats, souvent encodés en ASN.1, créant des défis pour :
- L'ingestion de données à grande échelle
- La standardisation des formats
- La réconciliation des revenus
- Les exigences de traitement en temps réel
Couche Bronze : Ingestion des Données Brutes
Composants de l'Architecture
La couche Bronze capture les CDR bruts des éléments réseau en utilisant une combinaison d'Apache NiFi pour l'orchestration et d'Apache Spark pour le traitement.
Stack Technologique :
- Apache NiFi : Orchestration et routage des flux de données
- Apache Spark : Moteur de traitement distribué
- Processeur ASN.1 Personnalisé : Décodage et parsing des CDR
- Stockage Objet : Persistance des données brutes (S3/HDFS)
Workflow d'Implémentation
# Vue d'ensemble du flux NiFi
# 1. GetFile/GetSFTP → Surveiller les répertoires CDR des éléments réseau
# 2. RouteOnAttribute → Classer par type de CDR (MSC, GGSN, OCS)
# 3. InvokeSparkJob → Déclencher le processus de décodage ASN.1
# 4. PutIceberg → Stocker les CDR décodés bruts
Processeur CDR ASN.1 Personnalisé
Le processeur Spark personnalisé gère le décodage ASN.1 pour différents formats de CDR :
// Job Spark : Décodeur CDR ASN.1
object CDRDecoder {
def decodeCDR(rawBytes: Array[Byte], cdrType: String): DataFrame = {
val decoder = cdrType match {
case "MSC" => new MSCDecoder()
case "GGSN" => new GGSNDecoder()
case "OCS" => new OCSDecoder()
case _ => throw new UnsupportedCDRException(cdrType)
}
decoder.parse(rawBytes)
.withColumn("ingestion_timestamp", current_timestamp())
.withColumn("source_system", lit(cdrType))
.withColumn("file_name", input_file_name())
}
}
Configuration du Pipeline NiFi
Processeurs Clés :
- GetFile/GetSFTP : Surveiller les répertoires CDR du MSC, GGSN, SMSC, OCS
- RouteOnAttribute : Classifier les CDR par type d'élément réseau
- ExecuteSparkInteractive : Invoquer les jobs de décodage ASN.1
- PutIceberg : Écrire les enregistrements décodés dans les tables Bronze
Caractéristiques de la Couche Bronze :
- Données CDR brutes préservées dans leur structure originale
- Enrichissement de métadonnées (heure d'ingestion, système source, suivi de fichiers)
- Archive historique immuable pour audit et retraitement
- Partitionnée par date et système source pour une récupération optimale
Couche Silver : Nettoyage et Corrélation des Données
Tables Iceberg pour la Couche Silver
Apache Iceberg fournit des transactions ACID et l'évolution de schéma, ce qui le rend idéal pour la couche Silver où la qualité et la cohérence des données sont critiques.
Tables de la Couche Silver :
silver.cdr_voice_msc- CDR vocaux du MSCsilver.cdr_voice_ocs- Événements de taxation vocale de l'OCSsilver.cdr_sms_smsc- Enregistrements SMS du SMSCsilver.cdr_data_ggsn- Enregistrements de sessions de données du GGSNsilver.cdr_data_ocs- Événements de taxation de données de l'OCS
Traitement Spark pour la Couche Silver
# Job Spark : Transformation Bronze vers Silver
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession.builder \
.appName("CDR_Silver_Processing") \
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.spark_catalog",
"org.apache.iceberg.spark.SparkSessionCatalog") \
.getOrCreate()
# Lecture depuis Bronze
bronze_msc = spark.read.format("iceberg") \
.load("bronze.raw_cdr_msc")
# Nettoyage et standardisation
silver_voice_msc = bronze_msc \
.filter(col("record_type").isNotNull()) \
.withColumn("calling_number", regexp_replace("calling_number", "[^0-9+]", "")) \
.withColumn("called_number", regexp_replace("called_number", "[^0-9+]", "")) \
.withColumn("call_duration", col("call_duration").cast("integer")) \
.withColumn("call_start_time", to_timestamp("call_start_time")) \
.dropDuplicates(["record_id", "call_start_time"]) \
.withColumn("processed_timestamp", current_timestamp())
# Écriture dans la table Silver Iceberg
silver_voice_msc.writeTo("silver.cdr_voice_msc") \
.using("iceberg") \
.partitionedBy(days("call_start_time")) \
.createOrReplace()
Règles de Qualité des Données
La couche Silver implémente des contrôles de qualité des données cruciaux :
# Framework de Qualité des Données
quality_checks = {
"completeness": ["calling_number", "called_number", "call_start_time"],
"validity": {
"call_duration": lambda x: x >= 0,
"calling_number": lambda x: len(x) >= 10
},
"consistency": {
"call_end_time": lambda row: row.call_end_time >= row.call_start_time
}
}
Assurance Revenus avec dbt
Couche Bronze dans le Contexte dbt
Dans notre architecture, dbt opère sur les tables Silver Iceberg (qui servent de couche "source" ou "bronze" du point de vue de dbt) pour créer des modèles d'assurance revenus.
Structure du Projet dbt
# dbt_project.yml
name: 'telecom_revenue_assurance'
version: '1.0.0'
config-version: 2
models:
telecom_revenue_assurance:
staging:
+materialized: view
+schema: bronze
marts:
revenue_assurance:
+materialized: table
+schema: gold
analytics:
+materialized: table
+schema: gold
Modèles de Staging (Couche Bronze dbt)
Créer des modèles de staging qui préparent les données Silver pour la corrélation de revenus :
-- models/staging/stg_voice_msc.sql
{{ config(materialized='view') }}
SELECT
record_id,
calling_number,
called_number,
call_start_time,
call_duration,
msc_id,
cell_id,
'MSC' as source_system,
processed_timestamp
FROM {{ source('silver', 'cdr_voice_msc') }}
WHERE call_start_time >= current_date - interval '7' day
-- models/staging/stg_voice_ocs.sql
{{ config(materialized='view') }}
SELECT
charging_id,
msisdn as calling_number,
called_party as called_number,
event_timestamp as call_start_time,
charged_duration,
charged_amount,
'OCS' as source_system,
processed_timestamp
FROM {{ source('silver', 'cdr_voice_ocs') }}
WHERE event_timestamp >= current_date - interval '7' day
Modèles de Corrélation pour l'Assurance Revenus
Assurance Revenus Voix et SMS :
-- models/marts/revenue_assurance/ra_voice_correlation.sql
{{ config(
materialized='incremental',
unique_key='correlation_id',
partition_by={
"field": "event_date",
"data_type": "date"
}
) }}
WITH msc_records AS (
SELECT * FROM {{ ref('stg_voice_msc') }}
),
ocs_records AS (
SELECT * FROM {{ ref('stg_voice_ocs') }}
),
correlated AS (
SELECT
m.record_id as msc_record_id,
o.charging_id as ocs_charging_id,
m.calling_number,
m.called_number,
m.call_start_time,
m.call_duration as msc_duration,
o.charged_duration as ocs_duration,
o.charged_amount,
CASE
WHEN o.charging_id IS NULL THEN 'MISSING_IN_OCS'
WHEN abs(m.call_duration - o.charged_duration) > 5 THEN 'DURATION_MISMATCH'
ELSE 'MATCHED'
END as correlation_status,
abs(m.call_duration - o.charged_duration) as duration_variance,
date(m.call_start_time) as event_date,
{{ dbt_utils.generate_surrogate_key(['m.record_id', 'o.charging_id']) }} as correlation_id
FROM msc_records m
LEFT JOIN ocs_records o
ON m.calling_number = o.calling_number
AND m.called_number = o.called_number
AND abs(unix_timestamp(m.call_start_time) - unix_timestamp(o.call_start_time)) <= 30
)
SELECT * FROM correlated
{% if is_incremental() %}
WHERE event_date > (SELECT max(event_date) FROM {{ this }})
{% endif %}
Assurance Revenus Sessions de Données :
-- models/marts/revenue_assurance/ra_data_correlation.sql
{{ config(
materialized='incremental',
unique_key='correlation_id',
partition_by={
"field": "session_date",
"data_type": "date"
}
) }}
WITH ggsn_sessions AS (
SELECT
session_id,
imsi,
msisdn,
session_start_time,
session_end_time,
data_volume_uplink,
data_volume_downlink,
(data_volume_uplink + data_volume_downlink) as total_volume,
apn,
'GGSN' as source_system
FROM {{ source('silver', 'cdr_data_ggsn') }}
),
ocs_charging AS (
SELECT
charging_session_id,
imsi,
msisdn,
charging_start_time,
charged_volume,
charged_amount,
service_identifier,
'OCS' as source_system
FROM {{ source('silver', 'cdr_data_ocs') }}
),
correlated AS (
SELECT
g.session_id as ggsn_session_id,
o.charging_session_id as ocs_session_id,
g.imsi,
g.msisdn,
g.session_start_time,
g.total_volume as ggsn_volume_bytes,
o.charged_volume as ocs_volume_bytes,
o.charged_amount,
g.apn,
CASE
WHEN o.charging_session_id IS NULL THEN 'MISSING_IN_OCS'
WHEN abs(g.total_volume - o.charged_volume) > (g.total_volume * 0.05) THEN 'VOLUME_MISMATCH'
WHEN o.charged_amount = 0 THEN 'ZERO_CHARGE'
ELSE 'MATCHED'
END as correlation_status,
abs(g.total_volume - o.charged_volume) as volume_variance_bytes,
CASE
WHEN g.total_volume > 0
THEN abs(g.total_volume - o.charged_volume) / g.total_volume * 100
ELSE 0
END as volume_variance_percent,
date(g.session_start_time) as session_date,
{{ dbt_utils.generate_surrogate_key(['g.session_id', 'o.charging_session_id']) }} as correlation_id
FROM ggsn_sessions g
LEFT JOIN ocs_charging o
ON g.imsi = o.imsi
AND abs(unix_timestamp(g.session_start_time) - unix_timestamp(o.charging_start_time)) <= 60
)
SELECT * FROM correlated
{% if is_incremental() %}
WHERE session_date > (SELECT max(session_date) FROM {{ this }})
{% endif %}
Tests dbt pour l'Assurance Revenus
# models/marts/revenue_assurance/schema.yml
version: 2
models:
- name: ra_voice_correlation
description: "Corrélation des CDR vocaux entre MSC et OCS pour l'assurance revenus"
columns:
- name: correlation_id
description: "Identifiant unique pour chaque enregistrement de corrélation"
tests:
- unique
- not_null
- name: correlation_status
description: "Statut de corrélation (MATCHED, MISSING_IN_OCS, DURATION_MISMATCH)"
tests:
- accepted_values:
values: ['MATCHED', 'MISSING_IN_OCS', 'DURATION_MISMATCH']
- name: duration_variance
description: "Différence en secondes entre la durée MSC et OCS"
tests:
- dbt_utils.expression_is_true:
expression: ">= 0"
- name: ra_data_correlation
description: "Corrélation des sessions de données entre GGSN et OCS pour l'assurance revenus"
columns:
- name: correlation_id
tests:
- unique
- not_null
- name: volume_variance_percent
description: "Pourcentage de variance du volume de données entre GGSN et OCS"
tests:
- dbt_utils.expression_is_true:
expression: ">= 0 AND <= 100"
Couche Gold : Métriques Métier Agrégées
Modèles de Couche Gold dbt
Créer des métriques agrégées optimisées pour la visualisation BI :
-- models/marts/analytics/gold_revenue_daily_summary.sql
{{ config(
materialized='table',
partition_by={
"field": "report_date",
"data_type": "date"
}
) }}
WITH voice_revenue AS (
SELECT
event_date as report_date,
COUNT(*) as total_voice_calls,
COUNT(CASE WHEN correlation_status = 'MATCHED' THEN 1 END) as matched_calls,
COUNT(CASE WHEN correlation_status = 'MISSING_IN_OCS' THEN 1 END) as missing_in_ocs,
COUNT(CASE WHEN correlation_status = 'DURATION_MISMATCH' THEN 1 END) as duration_mismatches,
SUM(charged_amount) as total_voice_revenue,
SUM(CASE WHEN correlation_status != 'MATCHED' THEN charged_amount ELSE 0 END) as revenue_at_risk
FROM {{ ref('ra_voice_correlation') }}
GROUP BY event_date
),
data_revenue AS (
SELECT
session_date as report_date,
COUNT(*) as total_data_sessions,
COUNT(CASE WHEN correlation_status = 'MATCHED' THEN 1 END) as matched_sessions,
COUNT(CASE WHEN correlation_status = 'MISSING_IN_OCS' THEN 1 END) as missing_in_ocs,
COUNT(CASE WHEN correlation_status = 'VOLUME_MISMATCH' THEN 1 END) as volume_mismatches,
SUM(ggsn_volume_bytes) / (1024*1024*1024) as total_data_gb,
SUM(charged_amount) as total_data_revenue,
SUM(CASE WHEN correlation_status != 'MATCHED' THEN charged_amount ELSE 0 END) as revenue_at_risk
FROM {{ ref('ra_data_correlation') }}
GROUP BY session_date
)
SELECT
COALESCE(v.report_date, d.report_date) as report_date,
-- Métriques Voix
COALESCE(v.total_voice_calls, 0) as total_voice_calls,
COALESCE(v.matched_calls, 0) as voice_matched_calls,
COALESCE(v.missing_in_ocs, 0) as voice_missing_in_ocs,
COALESCE(v.duration_mismatches, 0) as voice_duration_mismatches,
COALESCE(v.total_voice_revenue, 0) as total_voice_revenue,
COALESCE(v.revenue_at_risk, 0) as voice_revenue_at_risk,
-- Métriques Data
COALESCE(d.total_data_sessions, 0) as total_data_sessions,
COALESCE(d.matched_sessions, 0) as data_matched_sessions,
COALESCE(d.missing_in_ocs, 0) as data_missing_in_ocs,
COALESCE(d.volume_mismatches, 0) as data_volume_mismatches,
COALESCE(d.total_data_gb, 0) as total_data_gb,
COALESCE(d.total_data_revenue, 0) as total_data_revenue,
COALESCE(d.revenue_at_risk, 0) as data_revenue_at_risk,
-- Métriques Combinées
COALESCE(v.total_voice_revenue, 0) + COALESCE(d.total_data_revenue, 0) as total_revenue,
COALESCE(v.revenue_at_risk, 0) + COALESCE(d.revenue_at_risk, 0) as total_revenue_at_risk,
-- KPIs
CASE
WHEN COALESCE(v.total_voice_calls, 0) > 0
THEN COALESCE(v.matched_calls, 0) * 100.0 / v.total_voice_calls
ELSE 0
END as voice_match_rate_pct,
CASE
WHEN COALESCE(d.total_data_sessions, 0) > 0
THEN COALESCE(d.matched_sessions, 0) * 100.0 / d.total_data_sessions
ELSE 0
END as data_match_rate_pct
FROM voice_revenue v
FULL OUTER JOIN data_revenue d ON v.report_date = d.report_date
Analytique Abonnés :
-- models/marts/analytics/gold_subscriber_usage_summary.sql
{{ config(
materialized='table',
partition_by={
"field": "report_date",
"data_type": "date"
}
) }}
WITH voice_usage AS (
SELECT
calling_number as msisdn,
event_date as report_date,
COUNT(*) as voice_call_count,
SUM(msc_duration) as total_voice_minutes,
SUM(charged_amount) as voice_revenue
FROM {{ ref('ra_voice_correlation') }}
WHERE correlation_status = 'MATCHED'
GROUP BY calling_number, event_date
),
data_usage AS (
SELECT
msisdn,
session_date as report_date,
COUNT(*) as data_session_count,
SUM(ggsn_volume_bytes) / (1024*1024*1024) as total_data_gb,
SUM(charged_amount) as data_revenue
FROM {{ ref('ra_data_correlation') }}
WHERE correlation_status = 'MATCHED'
GROUP BY msisdn, session_date
)
SELECT
COALESCE(v.msisdn, d.msisdn) as msisdn,
COALESCE(v.report_date, d.report_date) as report_date,
COALESCE(v.voice_call_count, 0) as voice_call_count,
COALESCE(v.total_voice_minutes, 0) as total_voice_minutes,
COALESCE(v.voice_revenue, 0) as voice_revenue,
COALESCE(d.data_session_count, 0) as data_session_count,
COALESCE(d.total_data_gb, 0) as total_data_gb,
COALESCE(d.data_revenue, 0) as data_revenue,
COALESCE(v.voice_revenue, 0) + COALESCE(d.data_revenue, 0) as total_revenue,
-- Segmentation Abonnés
CASE
WHEN COALESCE(v.voice_revenue, 0) + COALESCE(d.data_revenue, 0) > 100 THEN 'HIGH_VALUE'
WHEN COALESCE(v.voice_revenue, 0) + COALESCE(d.data_revenue, 0) > 50 THEN 'MEDIUM_VALUE'
ELSE 'LOW_VALUE'
END as subscriber_segment
FROM voice_usage v
FULL OUTER JOIN data_usage d
ON v.msisdn = d.msisdn
AND v.report_date = d.report_date
Couche de Visualisation
Les tables de la couche Gold sont consommées par divers outils BI :
Tableaux de Bord Power BI :
- Tableau de Bord Exécutif d'Assurance Revenus
- Analytique de Performance Réseau
- Analyse du Comportement des Abonnés
- Alertes de Détection de Fraude
Apache Superset :
- Monitoring des Revenus en Temps Réel
- Statut de Corrélation des CDR
- Performance des Éléments Réseau
- Tendances de Fuite de Revenus
Grafana :
- Métriques de Santé du Système
- Monitoring du Pipeline de Données
- Gestion des Alertes
- Suivi de Conformité SLA
Flux de Données de Bout en Bout
Le flux complet de données des éléments réseau à la business intelligence :
- Éléments Réseau (MSC, GGSN, OCS) génèrent des CDR au format ASN.1
- Apache NiFi surveille et route les CDR vers les processeurs appropriés
- Spark avec Décodeur ASN.1 Personnalisé traite et décode les CDR
- Couche Bronze stocke les CDR décodés bruts avec métadonnées
- Transformations Spark nettoient et standardisent les données
- Couche Silver (Iceberg) maintient des CDR corrélés de haute qualité
- Modèles dbt effectuent la corrélation d'assurance revenus et l'agrégation
- Couche Gold fournit des métriques et KPI prêts pour le métier
- Outils BI (Power BI, Superset, Grafana) visualisent les insights
Stratégies d'Optimisation de Performance
Optimisation des Tables Iceberg
-- Optimiser les tables Iceberg régulièrement
CALL catalog_name.system.rewrite_data_files(
table => 'silver.cdr_voice_msc',
options => map('target-file-size-bytes', '536870912')
);
-- Expirer les anciens snapshots
CALL catalog_name.system.expire_snapshots(
table => 'silver.cdr_voice_msc',
older_than => TIMESTAMP '2025-10-01 00:00:00'
);
Traitement Incrémental dbt
-- Les modèles incrémentaux réduisent le temps de traitement
{{ config(
materialized='incremental',
incremental_strategy='merge',
unique_key='correlation_id'
) }}
Stratégie de Partitionnement
- Bronze : Partitionner par
ingestion_dateetsource_system - Silver : Partitionner par
event_date(jours) - Gold : Partitionner par
report_date(jours)
Monitoring et Alertes
Métriques Clés à Surveiller
Santé du Pipeline de Données :
- Taux d'ingestion CDR (enregistrements/seconde)
- Latence de traitement (bout en bout)
- Tentatives de décodage échouées
- Échecs de contrôle qualité des données
KPIs d'Assurance Revenus :
- Taux de correspondance de corrélation (cible : >99%)
- Revenus à risque (quotidien/mensuel)
- Nombre d'enregistrements manquants
- Tendances de variance durée/volume
Performance Système :
- Temps d'exécution des jobs Spark
- Taille et croissance des tables Iceberg
- Durée d'exécution des modèles dbt
- Temps de réponse des requêtes BI
Règles d'Alertes
# Exemple de configuration d'alertes
alerts:
- name: "Taux de Corrélation Faible"
condition: "voice_match_rate_pct < 95"
severity: "HIGH"
notification: "email, slack"
- name: "Revenus à Risque Élevés"
condition: "total_revenue_at_risk > 10000"
severity: "CRITICAL"
notification: "email, pagerduty"
- name: "Retard de Traitement CDR"
condition: "processing_latency_minutes > 30"
severity: "MEDIUM"
notification: "slack"
Bonnes Pratiques et Recommandations
Qualité des Données
- Implémenter une validation complète à chaque couche
- Utiliser le time travel d'Iceberg pour le débogage et la récupération
- Maintenir la lignée des données de la source à la consommation
- Profilage régulier des données pour détecter les anomalies tôt
Performance
- Optimiser les tailles de fichiers (viser 100MB - 1GB par fichier)
- Utiliser un partitionnement approprié pour minimiser le scan de données
- Exploiter le caching Spark pour les données fréquemment accédées
- Planifier les exécutions dbt pendant les heures creuses
Assurance Revenus
- Définir des règles de corrélation claires avec les parties prenantes métier
- Établir des seuils de variance acceptables pour la durée et le volume
- Automatiser les workflows de gestion d'exceptions
- Rapports de réconciliation réguliers avec les équipes financières
Opérations
- Implémenter une gestion d'erreurs robuste et des mécanismes de retry
- Surveiller la fraîcheur des données avec des SLA
- Documenter les transformations de données et la logique métier
- Contrôle de version de tous les modèles dbt et jobs Spark
Conclusion
Cette implémentation d'architecture médaillon fournit aux opérateurs de télécommunications une plateforme moderne et évolutive pour le traitement des CDR et l'assurance revenus. En combinant les capacités d'orchestration d'Apache NiFi, la puissance de traitement de Spark, les garanties ACID d'Iceberg et le framework de transformation de dbt, les organisations peuvent :
- Traiter des milliards de CDR quotidiennement avec une faible latence
- Assurer l'exactitude des revenus grâce à une corrélation systématique
- Détecter et prévenir les fuites de revenus de manière proactive
- Évoluer horizontalement à mesure que les volumes de données augmentent
- Maintenir la qualité des données à travers toutes les couches
- Activer l'analytique en libre-service pour les utilisateurs métier
L'architecture supporte à la fois le traitement batch et en temps quasi-réel, la rendant adaptée à divers cas d'usage télécom au-delà de l'assurance revenus, notamment la détection de fraude, l'optimisation réseau et l'analytique client.