Implementing Medallion Architecture for Telecom Revenue Assurance
In the telecommunications industry, processing Call Detail Records (CDRs) efficiently and accurately is critical for revenue assurance, fraud detection, and network optimization. This article explores how to implement a modern medallion architecture using Apache NiFi, Spark, Iceberg tables, and dbt to build a scalable telecom data platform.
Architecture Overview
Our telecom data platform implements the medallion architecture pattern across three layers:
- Bronze Layer: Raw CDR ingestion using Apache NiFi and Spark with ASN.1 decoding
- Silver Layer: Cleansed and correlated data stored in Apache Iceberg tables
- Gold Layer: Aggregated business metrics prepared with dbt for BI visualization
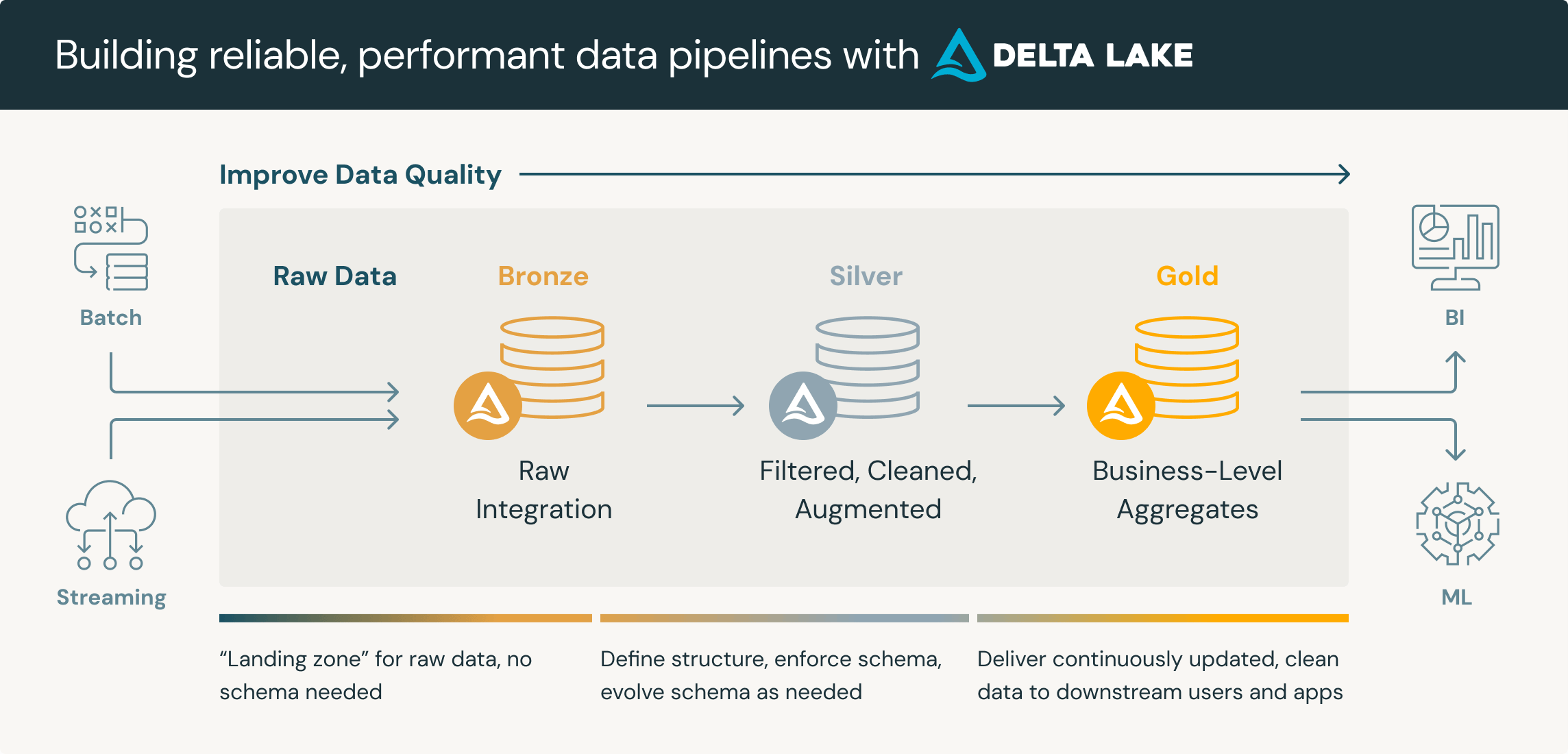
The Telecom Data Challenge
Telecommunications networks generate massive volumes of CDRs from multiple network elements:
- MSC (Mobile Switching Center): Voice call records
- SMSC (SMS Center): SMS/MMS records
- GGSN/PGW (Packet Gateway): Data session records
- OCS (Online Charging System): Real-time charging events
Each system produces CDRs in different formats, often encoded in ASN.1, creating challenges for:
- Data ingestion at scale
- Format standardization
- Revenue reconciliation
- Real-time processing requirements
Bronze Layer: Raw Data Ingestion
Architecture Components
The Bronze layer captures raw CDRs from network elements using a combination of Apache NiFi for orchestration and Apache Spark for processing.
Technology Stack:
- Apache NiFi: Data flow orchestration and routing
- Apache Spark: Distributed processing engine
- Custom ASN.1 Processor: CDR decoding and parsing
- Object Storage: Raw data persistence (S3/HDFS)
Implementation Workflow
# NiFi Flow Overview
# 1. GetFile/GetSFTP → Monitor CDR directories from network elements
# 2. RouteOnAttribute → Classify by CDR type (MSC, GGSN, OCS)
# 3. InvokeSparkJob → Trigger ASN.1 decoding process
# 4. PutIceberg → Store raw decoded CDRs
Custom ASN.1 CDR Processor
The custom Spark processor handles ASN.1 decoding for various CDR formats:
// Spark Job: ASN.1 CDR Decoder
object CDRDecoder {
def decodeCDR(rawBytes: Array[Byte], cdrType: String): DataFrame = {
val decoder = cdrType match {
case "MSC" => new MSCDecoder()
case "GGSN" => new GGSNDecoder()
case "OCS" => new OCSDecoder()
case _ => throw new UnsupportedCDRException(cdrType)
}
decoder.parse(rawBytes)
.withColumn("ingestion_timestamp", current_timestamp())
.withColumn("source_system", lit(cdrType))
.withColumn("file_name", input_file_name())
}
}
NiFi Pipeline Configuration
Key Processors:
- GetFile/GetSFTP: Poll CDR directories from MSC, GGSN, SMSC, OCS
- RouteOnAttribute: Classify CDRs by network element type
- ExecuteSparkInteractive: Invoke ASN.1 decoding jobs
- PutIceberg: Write decoded records to Bronze tables
Bronze Layer Characteristics:
- Raw CDR data preserved in original structure
- Metadata enrichment (ingestion time, source system, file tracking)
- Immutable historical archive for audit and reprocessing
- Partitioned by date and source system for optimal retrieval
Silver Layer: Data Cleansing and Correlation
Iceberg Tables for Silver Layer
Apache Iceberg provides ACID transactions and schema evolution, making it ideal for the Silver layer where data quality and consistency are critical.
Silver Layer Tables:
silver.cdr_voice_msc- Voice CDRs from MSCsilver.cdr_voice_ocs- Voice charging events from OCSsilver.cdr_sms_smsc- SMS records from SMSCsilver.cdr_data_ggsn- Data session records from GGSNsilver.cdr_data_ocs- Data charging events from OCS
Spark Processing for Silver Layer
# Spark Job: Bronze to Silver Transformation
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession.builder \
.appName("CDR_Silver_Processing") \
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.spark_catalog",
"org.apache.iceberg.spark.SparkSessionCatalog") \
.getOrCreate()
# Read from Bronze
bronze_msc = spark.read.format("iceberg") \
.load("bronze.raw_cdr_msc")
# Cleanse and standardize
silver_voice_msc = bronze_msc \
.filter(col("record_type").isNotNull()) \
.withColumn("calling_number", regexp_replace("calling_number", "[^0-9+]", "")) \
.withColumn("called_number", regexp_replace("called_number", "[^0-9+]", "")) \
.withColumn("call_duration", col("call_duration").cast("integer")) \
.withColumn("call_start_time", to_timestamp("call_start_time")) \
.dropDuplicates(["record_id", "call_start_time"]) \
.withColumn("processed_timestamp", current_timestamp())
# Write to Silver Iceberg table
silver_voice_msc.writeTo("silver.cdr_voice_msc") \
.using("iceberg") \
.partitionedBy(days("call_start_time")) \
.createOrReplace()
Data Quality Rules
Silver layer implements crucial data quality checks:
# Data Quality Framework
quality_checks = {
"completeness": ["calling_number", "called_number", "call_start_time"],
"validity": {
"call_duration": lambda x: x >= 0,
"calling_number": lambda x: len(x) >= 10
},
"consistency": {
"call_end_time": lambda row: row.call_end_time >= row.call_start_time
}
}
Revenue Assurance with dbt
Bronze Layer in dbt Context
In our architecture, dbt operates on the Silver Iceberg tables (which serve as dbt's "source" or "bronze" layer from dbt's perspective) to create revenue assurance models.
dbt Project Structure
# dbt_project.yml
name: 'telecom_revenue_assurance'
version: '1.0.0'
config-version: 2
models:
telecom_revenue_assurance:
staging:
+materialized: view
+schema: bronze
marts:
revenue_assurance:
+materialized: table
+schema: gold
analytics:
+materialized: table
+schema: gold
Staging Models (dbt Bronze Layer)
Create staging models that prepare Silver data for revenue correlation:
-- models/staging/stg_voice_msc.sql
{{ config(materialized='view') }}
SELECT
record_id,
calling_number,
called_number,
call_start_time,
call_duration,
msc_id,
cell_id,
'MSC' as source_system,
processed_timestamp
FROM {{ source('silver', 'cdr_voice_msc') }}
WHERE call_start_time >= current_date - interval '7' day
-- models/staging/stg_voice_ocs.sql
{{ config(materialized='view') }}
SELECT
charging_id,
msisdn as calling_number,
called_party as called_number,
event_timestamp as call_start_time,
charged_duration,
charged_amount,
'OCS' as source_system,
processed_timestamp
FROM {{ source('silver', 'cdr_voice_ocs') }}
WHERE event_timestamp >= current_date - interval '7' day
Revenue Assurance Correlation Models
Voice and SMS Revenue Assurance:
-- models/marts/revenue_assurance/ra_voice_correlation.sql
{{ config(
materialized='incremental',
unique_key='correlation_id',
partition_by={
"field": "event_date",
"data_type": "date"
}
) }}
WITH msc_records AS (
SELECT * FROM {{ ref('stg_voice_msc') }}
),
ocs_records AS (
SELECT * FROM {{ ref('stg_voice_ocs') }}
),
correlated AS (
SELECT
m.record_id as msc_record_id,
o.charging_id as ocs_charging_id,
m.calling_number,
m.called_number,
m.call_start_time,
m.call_duration as msc_duration,
o.charged_duration as ocs_duration,
o.charged_amount,
CASE
WHEN o.charging_id IS NULL THEN 'MISSING_IN_OCS'
WHEN abs(m.call_duration - o.charged_duration) > 5 THEN 'DURATION_MISMATCH'
ELSE 'MATCHED'
END as correlation_status,
abs(m.call_duration - o.charged_duration) as duration_variance,
date(m.call_start_time) as event_date,
{{ dbt_utils.generate_surrogate_key(['m.record_id', 'o.charging_id']) }} as correlation_id
FROM msc_records m
LEFT JOIN ocs_records o
ON m.calling_number = o.calling_number
AND m.called_number = o.called_number
AND abs(unix_timestamp(m.call_start_time) - unix_timestamp(o.call_start_time)) <= 30
)
SELECT * FROM correlated
{% if is_incremental() %}
WHERE event_date > (SELECT max(event_date) FROM {{ this }})
{% endif %}
Data Session Revenue Assurance:
-- models/marts/revenue_assurance/ra_data_correlation.sql
{{ config(
materialized='incremental',
unique_key='correlation_id',
partition_by={
"field": "session_date",
"data_type": "date"
}
) }}
WITH ggsn_sessions AS (
SELECT
session_id,
imsi,
msisdn,
session_start_time,
session_end_time,
data_volume_uplink,
data_volume_downlink,
(data_volume_uplink + data_volume_downlink) as total_volume,
apn,
'GGSN' as source_system
FROM {{ source('silver', 'cdr_data_ggsn') }}
),
ocs_charging AS (
SELECT
charging_session_id,
imsi,
msisdn,
charging_start_time,
charged_volume,
charged_amount,
service_identifier,
'OCS' as source_system
FROM {{ source('silver', 'cdr_data_ocs') }}
),
correlated AS (
SELECT
g.session_id as ggsn_session_id,
o.charging_session_id as ocs_session_id,
g.imsi,
g.msisdn,
g.session_start_time,
g.total_volume as ggsn_volume_bytes,
o.charged_volume as ocs_volume_bytes,
o.charged_amount,
g.apn,
CASE
WHEN o.charging_session_id IS NULL THEN 'MISSING_IN_OCS'
WHEN abs(g.total_volume - o.charged_volume) > (g.total_volume * 0.05) THEN 'VOLUME_MISMATCH'
WHEN o.charged_amount = 0 THEN 'ZERO_CHARGE'
ELSE 'MATCHED'
END as correlation_status,
abs(g.total_volume - o.charged_volume) as volume_variance_bytes,
CASE
WHEN g.total_volume > 0
THEN abs(g.total_volume - o.charged_volume) / g.total_volume * 100
ELSE 0
END as volume_variance_percent,
date(g.session_start_time) as session_date,
{{ dbt_utils.generate_surrogate_key(['g.session_id', 'o.charging_session_id']) }} as correlation_id
FROM ggsn_sessions g
LEFT JOIN ocs_charging o
ON g.imsi = o.imsi
AND abs(unix_timestamp(g.session_start_time) - unix_timestamp(o.charging_start_time)) <= 60
)
SELECT * FROM correlated
{% if is_incremental() %}
WHERE session_date > (SELECT max(session_date) FROM {{ this }})
{% endif %}
dbt Testing for Revenue Assurance
# models/marts/revenue_assurance/schema.yml
version: 2
models:
- name: ra_voice_correlation
description: "Voice CDR correlation between MSC and OCS for revenue assurance"
columns:
- name: correlation_id
description: "Unique identifier for each correlation record"
tests:
- unique
- not_null
- name: correlation_status
description: "Status of correlation (MATCHED, MISSING_IN_OCS, DURATION_MISMATCH)"
tests:
- accepted_values:
values: ['MATCHED', 'MISSING_IN_OCS', 'DURATION_MISMATCH']
- name: duration_variance
description: "Difference in seconds between MSC and OCS duration"
tests:
- dbt_utils.expression_is_true:
expression: ">= 0"
- name: ra_data_correlation
description: "Data session correlation between GGSN and OCS for revenue assurance"
columns:
- name: correlation_id
tests:
- unique
- not_null
- name: volume_variance_percent
description: "Percentage variance in data volume between GGSN and OCS"
tests:
- dbt_utils.expression_is_true:
expression: ">= 0 AND <= 100"
Gold Layer: Aggregated Business Metrics
dbt Gold Layer Models
Create aggregated metrics optimized for BI visualization:
-- models/marts/analytics/gold_revenue_daily_summary.sql
{{ config(
materialized='table',
partition_by={
"field": "report_date",
"data_type": "date"
}
) }}
WITH voice_revenue AS (
SELECT
event_date as report_date,
COUNT(*) as total_voice_calls,
COUNT(CASE WHEN correlation_status = 'MATCHED' THEN 1 END) as matched_calls,
COUNT(CASE WHEN correlation_status = 'MISSING_IN_OCS' THEN 1 END) as missing_in_ocs,
COUNT(CASE WHEN correlation_status = 'DURATION_MISMATCH' THEN 1 END) as duration_mismatches,
SUM(charged_amount) as total_voice_revenue,
SUM(CASE WHEN correlation_status != 'MATCHED' THEN charged_amount ELSE 0 END) as revenue_at_risk
FROM {{ ref('ra_voice_correlation') }}
GROUP BY event_date
),
data_revenue AS (
SELECT
session_date as report_date,
COUNT(*) as total_data_sessions,
COUNT(CASE WHEN correlation_status = 'MATCHED' THEN 1 END) as matched_sessions,
COUNT(CASE WHEN correlation_status = 'MISSING_IN_OCS' THEN 1 END) as missing_in_ocs,
COUNT(CASE WHEN correlation_status = 'VOLUME_MISMATCH' THEN 1 END) as volume_mismatches,
SUM(ggsn_volume_bytes) / (1024*1024*1024) as total_data_gb,
SUM(charged_amount) as total_data_revenue,
SUM(CASE WHEN correlation_status != 'MATCHED' THEN charged_amount ELSE 0 END) as revenue_at_risk
FROM {{ ref('ra_data_correlation') }}
GROUP BY session_date
)
SELECT
COALESCE(v.report_date, d.report_date) as report_date,
-- Voice Metrics
COALESCE(v.total_voice_calls, 0) as total_voice_calls,
COALESCE(v.matched_calls, 0) as voice_matched_calls,
COALESCE(v.missing_in_ocs, 0) as voice_missing_in_ocs,
COALESCE(v.duration_mismatches, 0) as voice_duration_mismatches,
COALESCE(v.total_voice_revenue, 0) as total_voice_revenue,
COALESCE(v.revenue_at_risk, 0) as voice_revenue_at_risk,
-- Data Metrics
COALESCE(d.total_data_sessions, 0) as total_data_sessions,
COALESCE(d.matched_sessions, 0) as data_matched_sessions,
COALESCE(d.missing_in_ocs, 0) as data_missing_in_ocs,
COALESCE(d.volume_mismatches, 0) as data_volume_mismatches,
COALESCE(d.total_data_gb, 0) as total_data_gb,
COALESCE(d.total_data_revenue, 0) as total_data_revenue,
COALESCE(d.revenue_at_risk, 0) as data_revenue_at_risk,
-- Combined Metrics
COALESCE(v.total_voice_revenue, 0) + COALESCE(d.total_data_revenue, 0) as total_revenue,
COALESCE(v.revenue_at_risk, 0) + COALESCE(d.revenue_at_risk, 0) as total_revenue_at_risk,
-- KPIs
CASE
WHEN COALESCE(v.total_voice_calls, 0) > 0
THEN COALESCE(v.matched_calls, 0) * 100.0 / v.total_voice_calls
ELSE 0
END as voice_match_rate_pct,
CASE
WHEN COALESCE(d.total_data_sessions, 0) > 0
THEN COALESCE(d.matched_sessions, 0) * 100.0 / d.total_data_sessions
ELSE 0
END as data_match_rate_pct
FROM voice_revenue v
FULL OUTER JOIN data_revenue d ON v.report_date = d.report_date
Subscriber Analytics:
-- models/marts/analytics/gold_subscriber_usage_summary.sql
{{ config(
materialized='table',
partition_by={
"field": "report_date",
"data_type": "date"
}
) }}
WITH voice_usage AS (
SELECT
calling_number as msisdn,
event_date as report_date,
COUNT(*) as voice_call_count,
SUM(msc_duration) as total_voice_minutes,
SUM(charged_amount) as voice_revenue
FROM {{ ref('ra_voice_correlation') }}
WHERE correlation_status = 'MATCHED'
GROUP BY calling_number, event_date
),
data_usage AS (
SELECT
msisdn,
session_date as report_date,
COUNT(*) as data_session_count,
SUM(ggsn_volume_bytes) / (1024*1024*1024) as total_data_gb,
SUM(charged_amount) as data_revenue
FROM {{ ref('ra_data_correlation') }}
WHERE correlation_status = 'MATCHED'
GROUP BY msisdn, session_date
)
SELECT
COALESCE(v.msisdn, d.msisdn) as msisdn,
COALESCE(v.report_date, d.report_date) as report_date,
COALESCE(v.voice_call_count, 0) as voice_call_count,
COALESCE(v.total_voice_minutes, 0) as total_voice_minutes,
COALESCE(v.voice_revenue, 0) as voice_revenue,
COALESCE(d.data_session_count, 0) as data_session_count,
COALESCE(d.total_data_gb, 0) as total_data_gb,
COALESCE(d.data_revenue, 0) as data_revenue,
COALESCE(v.voice_revenue, 0) + COALESCE(d.data_revenue, 0) as total_revenue,
-- Subscriber Segmentation
CASE
WHEN COALESCE(v.voice_revenue, 0) + COALESCE(d.data_revenue, 0) > 100 THEN 'HIGH_VALUE'
WHEN COALESCE(v.voice_revenue, 0) + COALESCE(d.data_revenue, 0) > 50 THEN 'MEDIUM_VALUE'
ELSE 'LOW_VALUE'
END as subscriber_segment
FROM voice_usage v
FULL OUTER JOIN data_usage d
ON v.msisdn = d.msisdn
AND v.report_date = d.report_date
Visualization Layer
The Gold layer tables are consumed by various BI tools:
Power BI Dashboards:
- Revenue Assurance Executive Dashboard
- Network Performance Analytics
- Subscriber Behavior Analysis
- Fraud Detection Alerts
Apache Superset:
- Real-time Revenue Monitoring
- CDR Correlation Status
- Network Element Performance
- Revenue Leakage Trends
Grafana:
- System Health Metrics
- Data Pipeline Monitoring
- Alert Management
- SLA Compliance Tracking
End-to-End Data Flow
The complete data flow from network elements to business intelligence:
- Network Elements (MSC, GGSN, OCS) generate CDRs in ASN.1 format
- Apache NiFi monitors and routes CDRs to appropriate processors
- Spark with Custom ASN.1 Decoder processes and decodes CDRs
- Bronze Layer stores raw decoded CDRs with metadata
- Spark Transformations cleanse and standardize data
- Silver Layer (Iceberg) maintains high-quality, correlated CDRs
- dbt Models perform revenue assurance correlation and aggregation
- Gold Layer provides business-ready metrics and KPIs
- BI Tools (Power BI, Superset, Grafana) visualize insights
Performance Optimization Strategies
Iceberg Table Optimization
-- Optimize Iceberg tables regularly
CALL catalog_name.system.rewrite_data_files(
table => 'silver.cdr_voice_msc',
options => map('target-file-size-bytes', '536870912')
);
-- Expire old snapshots
CALL catalog_name.system.expire_snapshots(
table => 'silver.cdr_voice_msc',
older_than => TIMESTAMP '2025-10-01 00:00:00'
);
dbt Incremental Processing
-- Incremental models reduce processing time
{{ config(
materialized='incremental',
incremental_strategy='merge',
unique_key='correlation_id'
) }}
Partitioning Strategy
- Bronze: Partition by
ingestion_dateandsource_system - Silver: Partition by
event_date(days) - Gold: Partition by
report_date(days)
Monitoring and Alerting
Key Metrics to Monitor
Data Pipeline Health:
- CDR ingestion rate (records/second)
- Processing latency (end-to-end)
- Failed decoding attempts
- Data quality check failures
Revenue Assurance KPIs:
- Correlation match rate (target: >99%)
- Revenue at risk (daily/monthly)
- Missing records count
- Duration/volume variance trends
System Performance:
- Spark job execution time
- Iceberg table size and growth
- dbt model run duration
- BI query response times
Alerting Rules
# Example alert configuration
alerts:
- name: "Low Correlation Rate"
condition: "voice_match_rate_pct < 95"
severity: "HIGH"
notification: "email, slack"
- name: "High Revenue at Risk"
condition: "total_revenue_at_risk > 10000"
severity: "CRITICAL"
notification: "email, pagerduty"
- name: "CDR Processing Delay"
condition: "processing_latency_minutes > 30"
severity: "MEDIUM"
notification: "slack"
Best Practices and Recommendations
Data Quality
- Implement comprehensive validation at each layer
- Use Iceberg's time travel for debugging and recovery
- Maintain data lineage from source to consumption
- Regular data profiling to catch anomalies early
Performance
- Optimize file sizes (aim for 100MB - 1GB per file)
- Use appropriate partitioning to minimize data scanning
- Leverage Spark caching for frequently accessed data
- Schedule dbt runs during off-peak hours
Revenue Assurance
- Define clear correlation rules with business stakeholders
- Set acceptable variance thresholds for duration and volume
- Automate exception handling workflows
- Regular reconciliation reports with finance teams
Operations
- Implement robust error handling and retry mechanisms
- Monitor data freshness with SLAs
- Document data transformations and business logic
- Version control all dbt models and Spark jobs
Conclusion
This medallion architecture implementation provides telecommunications operators with a modern, scalable platform for CDR processing and revenue assurance. By combining Apache NiFi's orchestration capabilities, Spark's processing power, Iceberg's ACID guarantees, and dbt's transformation framework, organizations can:
- Process billions of CDRs daily with low latency
- Ensure revenue accuracy through systematic correlation
- Detect and prevent revenue leakage proactively
- Scale horizontally as data volumes grow
- Maintain data quality across all layers
- Enable self-service analytics for business users
The architecture supports both batch and near-real-time processing, making it suitable for various telecom use cases beyond revenue assurance, including fraud detection, network optimization, and customer analytics.